Attention Is All You Need, Building a Transformer for Thanglish-to-Tamil
Where We Left Off 📜
In my last post I built three architectures for “Thanglish to Tamil” Transliteration on the Google Dakshina Dataset using a Vanilla LSTM, a BiGRU with Attention, and a CNN-LSTM Architecture
The CNN-LSTM won that round, not because it was the most Accurate, but because it matched the others while being 16x smaller
But one Architecture was sitting in the corner the whole time, waiting 😏
(Optimus Prime)
💭 What if I just use the thing that Attention was actually made for?
So this weekend I built The Transformer the Original Encoder-Decoder one from Attention Is All You Need (Vaswani et al., 2017) from scratch using PyTorch
The Architecture 🏗️
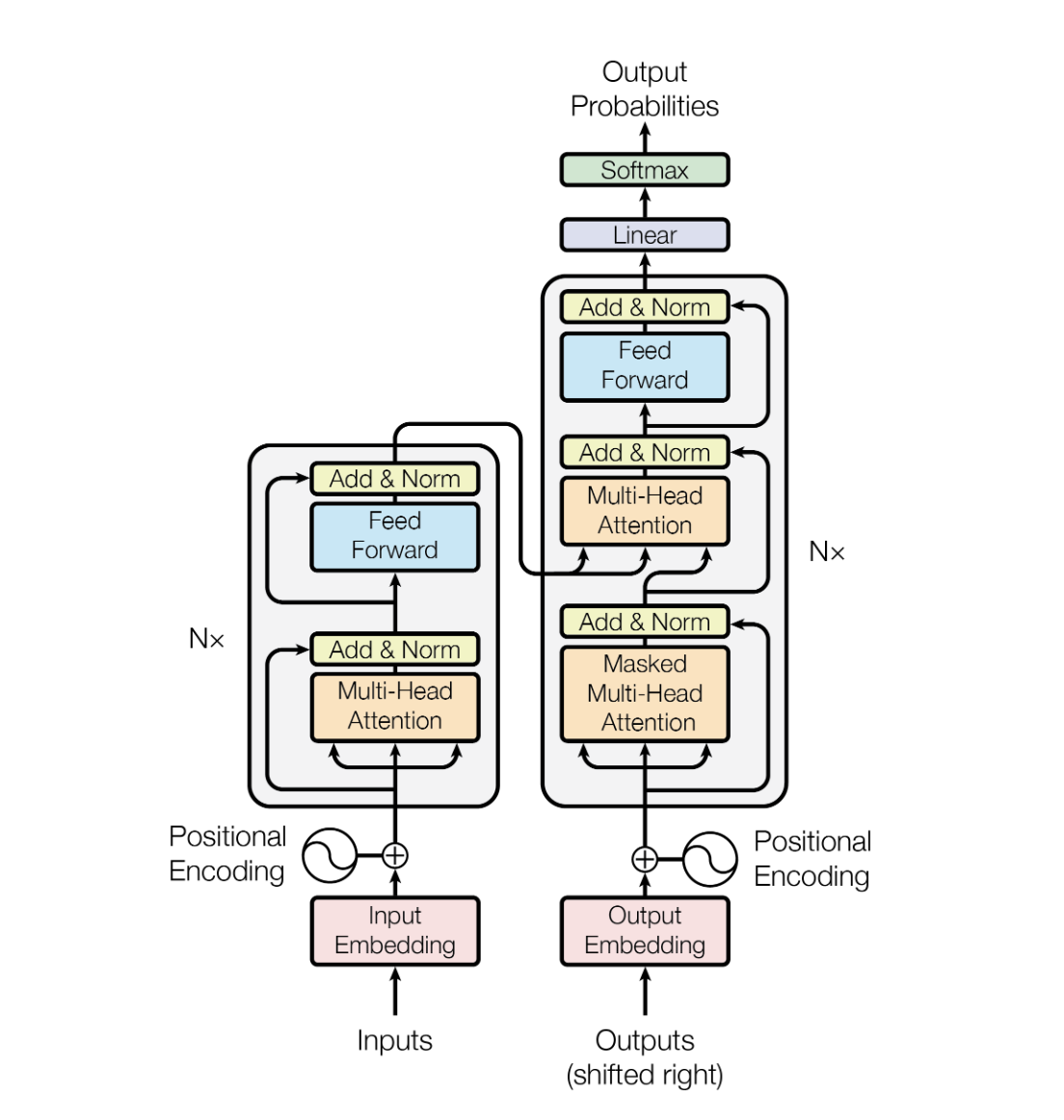
It is the Clasical Encoder-Decoder Transformer :
- Scaled Dot-Product Attention
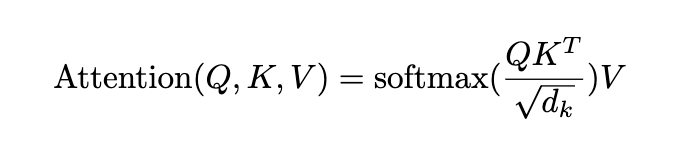
- Multi-Head Attention — 8 heads, separate
W_q, W_k, W_vand an output projectionW_o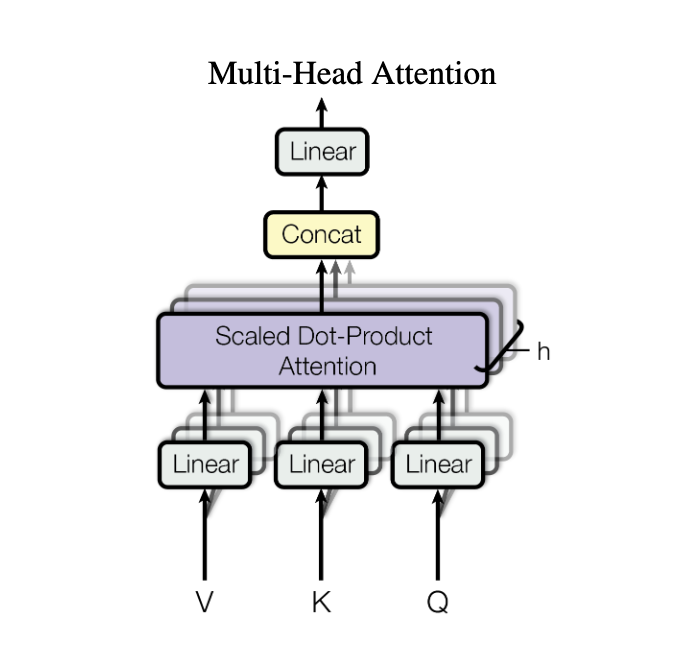
- Sinusoidal Positional Encoding
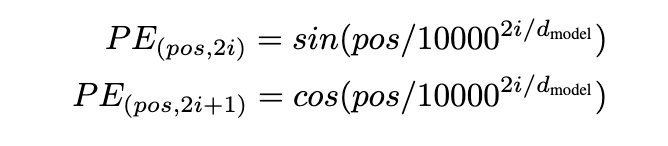
- Encoder
- Decoder
- Masking : A padding mask so we ignore
<PAD>, and a Causal Mask so the Decoder can’t peek at future Characters
🔧 Configuration :
d_model (Embedding Dim) : 256
n_heads (Attention Heads) : 8
n_layers (Encoder / Decoder) : 3
d_ff (Feed Forward Dim) : 512
dropout : 0.1
Same Character Level, same Seq2Seq setup as before
Evaluation 📈
Used Google Colab for Training
Note : Same as previous post, these Accuracy are not too high, I am just tweaking Hyperparameter like Regularization, with limited Compute Resource, just sharing the current progress here
Transformer (Encoder-Decoder)
Current Total Parameters : 3986994
Train Loss : 0.1178 | Val Loss : 0.3287 | Val Acc : 57.73% | Val CER : 15.49%
Test Exact Match Accuracy : 56.29% Test Character Error Rate : 15.92%
Val Accuracy was still climbing (60.14% on Dev Set) and Early Stopping stopped at epoch 48
Good
- Best Accuracy of every Model is Built
- Validation Loss in a Completely Different Improved
- Demo Outputs good
Bad
- Overfitting : Training Loss dropped to ~0.07 while Val Loss is around 0.33
- Still slips on like :
puthagamfor “புதகம்” instead of “புத்தகம்” - Second Heaviest Model seen so far
Fixes
Yes, there are few fixes we can do if we find time later
🏆 The Match : All Four Architectures
| Architecture | Parameters | Test Accuracy | Test CER | Val Loss |
|---|---|---|---|---|
| CNN-LSTM | 767,666 | 50.55% | 15.81% | 0.9868 |
| Vanilla LSTM | 1,411,890 | 51.57% | 16.36% | 1.4453 |
| Transformer | 3,986,994 | 56.29% | 15.92% | 0.3287 |
| BiGRU + Attention | 12,580,914 | 50.60% | 16.44% | 1.3492 |
So… Who Actually Wins? 🤷
This is where it gets fun, because the answer is two different Winners depending on the Question
. . . . . . . . . . . .
If the question is “Best Quality” : Transformer wins 🎉
It jumps to 56.29% accuracy : a +4.72 point lead over the next best (Vanilla LSTM)
It ties the CNN-LSTM on CER (15.92% vs 15.81% — noise)
Its Validation Loss (0.3287) shows it is genuinely Modelling the problem far better, not just Memorizing
If the question is “Best Efficiency” : CNN-LSTM still wins 🥳
The CNN-LSTM reaches CER at 1/5th the Parameters of the Transformer (and 16x smaller than BiGRU + Attention)
For Deployment, Inference Speed, and “does it earn its size” : Convolution still Rules
So my earlier Thesis survives, just with a footnote :
For local, “n-gram-driven Transliteration”, Convolution is the efficiency winner But when you can go for the the Parameters, global Attention is the Accuracy winner Right tool
And honestly : both are fixable further, Label Smoothing, Warmup, more Regularization could change this table again. That’s the whole point :
Because we need to Experiment and Find 🔬
Repository : https://github.com/ajithraghavan/VisAI
Please feel free to Clone, Use and Train on your own Dataset for Exploration
Thanks for reading!