Introduction
I Built a mini version of GPT (Generative Pre-trained Transformer) from scratch using PyTorch, and I used Thirukural : திருக்குறள் as the Dataset for training
And it’s the old post and I am posting now
Here is the Repository : https://github.com/ajithraghavan/ThirukuralGPT
What is GPT?
GPT(Generative Pre-trained Transformer) is a type of Model designed for NLP(Natural Language Processing) Developed by OpenAI it is based one of the remarkable architecture called Transformer, can you can read more about GPT here
What is Transformer?

Transformer is from “Attention Is All You Need” paper and it revolutionized NLP application
It revolutionlized because, unlike RNN(also GRU, LSTM) process words one by one (after predicting also, called Auto-Regressive(GPT is also Auto-Regressive but not BERT, but both are from Transformer Architecture)) it process entire sentences in parallel and decides which ones are most relevant to each other using Self-Attention Mechanism, making training much faster!
It has several components in it, and I will write some very briefly,
-
Input Embedding : Turns words into Number through Tokenization and Word Embedding(which itself is a big topic)
-
Positional Encoding : We process the words in parallel right, then how do the Model knows about word’s position? Here is where Positional Encoding came to rescue, it adds unique signal to each word based on its position(original paper uses Sine and Cosine Functions to Encode positions)
-
Self-Attention Mechanism : It allows the Model to weigh the importance of each word relative to other words by Computing Query(Q), Key(K), Value(V) Matrices for each word
-
Multi-Head Attention : So, instead of one attention layer, it uses multiple Self-Attention Heads, and each learn different relationships like may be grammar, semantics etc
-
Feed-Forward Neural Network : After we Attention pass the output through a Feed-Forward Neural Network to provide non-linearity to learn complex transformations
-
Add and Norm : It adds the Residual Connection or Skip Connection to help Gradient flow during Backpropagation and stabilizes training by normalizing activations
-
There are also Masked Multi-Head Attention and Softmax like those, which you can read on original paper
So, with that let me introduce you the one of the beautiful pictures, The Transformer 😍
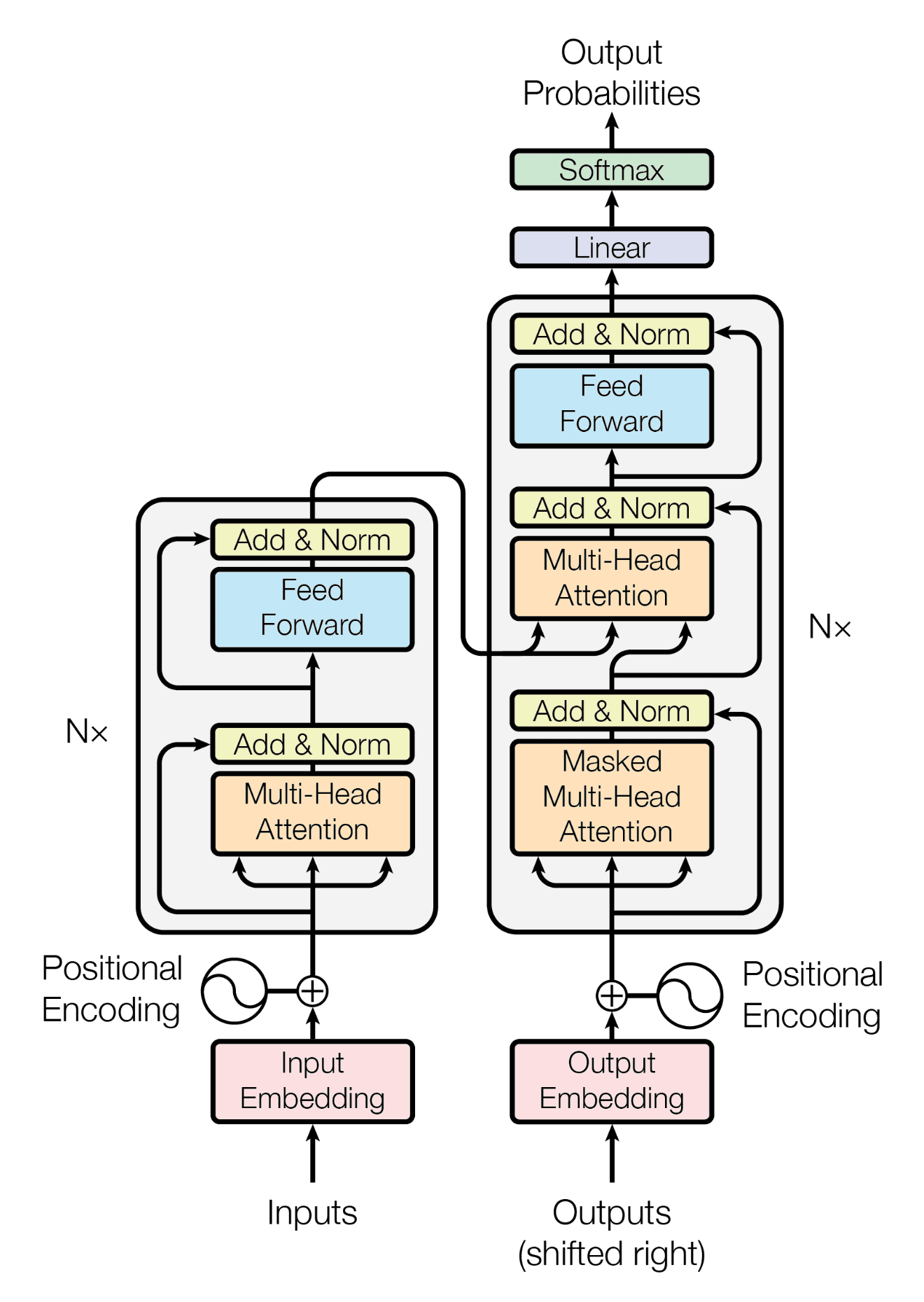
Wow, very nice right?
In the image if you split the image into two in centre then the left side is the Encoder and right side is the Decoder
Now, the left side of the Image is called Encoder Block and right side of the Image is called Decoder Block
If you take Encoder only Block and train it then it will become Encoder-only Transformer like BERT(Bidirectional Encoder Representations from Transformers), RoBERTa(Robustly Optimized BERT Pretraining Approach), etc
If you take Decoder only Block and train it then it will become Decoder-only Transformer like GPT, etc
And there are more I am excited to share more but let’s now come back to ThirukuralGPT
About ThirukuralGPT
Note : Here ThirukuralGPT not similar to ChatGPT, like we use for QA and summarizing like those
In case of ChatGPT it is first trained as same as ours but in more larger scale and with more number of Parameters after that they will use “Reward Model” and “PPO Reinforcement Learning” to further Fine-Tune the Model
Here ThirukuralGPT is trained as like the initial way like in ChatGPT but at a smaller scale and ThirukuralGPT could try to generate Thrirukural like words and sentences and don’t expect any meaning in those sentences
But have also did that by Fine-Turning the Pre-Trained Model, please take a look at here https://x.com/ajith2krishna/status/1762769058313977856?s=46&t=VRKTk5vNPGqgClt_PDdYnQ
I have downloaded the Thirukural from here, and cleaned little bit and used as the Dataset and used Kaggle for Training in GPU
As we say GPT is Decoder only Transformer so, I have written Written Vectorization like Token Embedding, Positional Encoding and Decoder Block, Generation Function in Python Program using PyTorch and started Training
Initially our Model was generating “அறமல்லுலகத்துண்ணாதா லவற்கு” like those
And we need to do some Hyperparameter Tuning to get the Thirukural like words and sentences
So, after doing some Hyperparameter Tuning, Rugularization, changing Block Size and Training even more, I started to see the words the GPT is generating like below,
நாணாசென் போர்த்து கண்தவின் வஞுத்தீன்து தக்றத் தாகும் அண். (7 Words)
நாணதாளில் கறிப்பதாத ல்லவார்க்கம் என்னிக் சிற்றென்றுப்லாரின் என்றாப் படனை. (7 Words)
ஈழியுப் பிறினுண டெல்லக்கி அடந்தாக்கல் பொற்றோர் பொய்வாக் குணை. (7 Words)
கூன்றுடு களப்படும் என்றால் நோக்கானும் அஃத முதனை. (6 Words)
இனந்துமை மழைந்தூர்க் கொள்ளவன் நாணோக்கு உலகத்து. (5 Words)
தனைந்துஞ்சால் கல்லவி நல்லயம் பயன்னும் செல்தொறித்தி யார தலை. (7 Words)
பட்டந்தபும் என்னார்நாடு நீர். (3 Words)
Note, at this point in training our Model started to know, that Thirukural only have Seven Words in a Sentence and our Model also tried to reproduce the same(yes, in some sentences it has few or more than seven words, but it figures beautifully, right)
And, please don’t hesitate to clone and train using your own Dataset
I have build ThrirukuralGPT taking prime inspiration from Andrej Karpathy Sensei video, also his videos are great for building things from scratch, if you find time please watch his videos, and you might learn more
Thanks for Reading!